
The Document Object Model (DOM)
So you just learned HTML for the first time and now, I'm throwing you a curve-ball. The Document Object Model, or "DOM" is the bridge between JavaScript and HTML.
Most web development courses teach HTML prior to teaching JavaScript, but I did the opposite because understanding the DOM without having a basic background in JavaScript is a fools errand. I learned HTML before JavaScript and when we got to the DOM section, I had NO IDEA what the instructor was talking about.
And that is a shame, because a strong understanding of the DOM will go a long way in today's world where front-end frameworks like React, Vue, and Angular dominate the web. All of these frameworks heavily leverage the DOM and the React framework even defines its own "virtual DOM".
Why are we talking about the DOM?
No matter what front-end framework you use, in some way or another, it will be leveraging the DOM. You may not see how that is happening due to layers of abstraction, but at the basis of every front-end application, the DOM is what allows us to connect our JavaScript to our HTML and make things happen.
While you don't need to be an expert in this topic, you should understand what the DOM is and how it plays into the code you are writing.
So what is the DOM (Document Object Model)?
The "DOM" is NOT a programming language. The "DOM" is also not part of JavaScript. So what is it?
The DOM is an API for an HTML document. What is an API? Here is the definition I came up with in my post explaining APIs:
A software API can be thought of as a "user manual" that allows developers to do something useful with 3rd party software/hardware without knowing the inner-workings of that software/hardware.
In other words, you want to do something programmatically with your webpage, but you don't want to become an expert in the low-level details of how HTML actually works (i.e. how it is actually rendered on a webpage, NOT how to write it).
I know your head is probably spinning, so let's make this real. Take a look at the following HTML document.
<html>
<head>
<title>My webpage</title>
</head>
<body>
<h2>Welcome to my HTML tutorial</h2>
<p>Click the button below to begin</p>
<button>Start Tutorial</button>
</body>
</html>
And here is what it looks like (I put some basic CSS styles on it, but again, don't worry about them YET).
Go ahead, click that button.
What does it do?
NOTHIN. IT'S USELESS.
If we want that button to do something, we need to bring in our friend, JavaScript. As we talked about earlier, JavaScript is what brings a webpage alive.
But how do we make that happen? Somehow, we need to identify that button HTML element and tell it to do something when someone clicks it. So it's a two step process:
- Identify an HTML element using JavaScript
- Once identified, instruct it to do something in JavaScript
Identifying HTML Elements with JavaScript
This is where the DOM comes in. As we said, the DOM is an API for accessing HTML elements.
Here's how we identify that button:
const btn = document.querySelector("button");
This is JavaScript running in your web browser, and all we are doing is assigning our identified HTML element to a variable called btn. But what is document? And what is this querySelector() method on it?
An Analogy for Understanding the DOM (Document Object Model)
At this point, I'm assuming you kind of understand what I'm saying, but it's still fuzzy. That's okay.
To aid our discussion, think of an HTML document as a paper map, and think of the DOM combined with HTML as Google Maps.
With Google Maps, we can build applications like Uber because it has a pre-defined structure (API) for using it! We can "plug in" all sorts of integrations.
An HTML document is a bit boring on its own; just like a paper map. But once we define a structural representation of that HTML document (the DOM), we have unlimited possibilities!
The Structure of the DOM (HINT: it's a tree!)
We call this a String object in JavaScript:
const str = "some string";
We call this a Number object in JavaScript:
const num = 20;
We call this an null primitive in JavaScript:
let someVar = null;
And we call this an HTMLElement object in JavaScript:
const btn = document.querySelector("button");
The HTMLElement data type is not native to JavaScript. It's not even available in server-side (NodeJS) JavaScript! So what is it?
This is just one of many "leaves" that makes up the "DOM Tree". More on this soon.
A 10,000 Foot View of the DOM
Before we get into this, let me give you four things to consider as we explore this:
- The DOM is complex, and at your current skill level (assuming you're following along with this series), you will NOT fully grasp it. That's okay. Try to follow the high-level themes, but don't stress over the details. This will not make or break your ability to program web apps.
- The DOM is not part of the JavaScript programming language (but can be used by it; hence why we call it an "API")
- Each browser has a slightly different implementation of the DOM, but these differences shouldn't matter to most web developers.
- The DOM is not a programming language, but rather a "model" or "representation" of an existing structure (HTML). It adapts a lot of OOP (Object Oriented Programming) concepts which can be confusing since we haven't learned it yet, but just remember, each piece of the HTML can be "modeled" according to properties and methods (what it is made of and what it can do).
To understand this as a beginner, we're going to need some visuals and work our way slowly into the details.
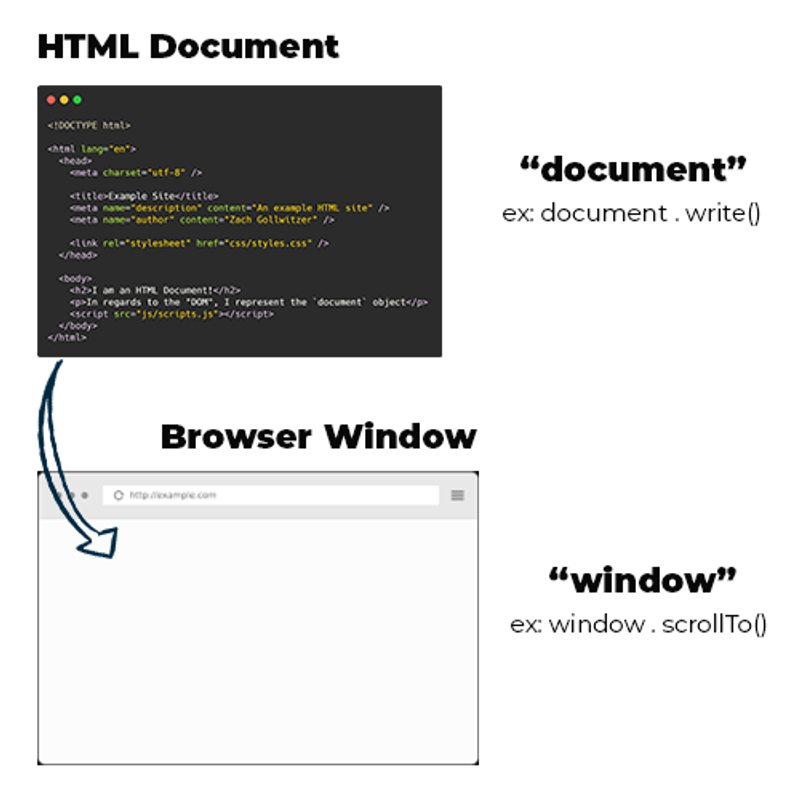
First, I want you to get clear on a couple of things.
- The browser itself is programmable
- Each browser tab contains exactly 1 HTML "Document" (this is technically not true if you have an
iframe, but not important here)
The Window Object
So what can that browser of yours do that you would want to program? Here are a few ideas:
We can...
- Scroll up and down through the content of a webpage
- Refresh the page
- Resize the browser window
And the best part? We can write JavaScript to do this via the DOM.
To programmatically control the browser itself, we will use a global DOM object called window.
Here is the link to its official documentation that I recommend you quickly glance at.
Per the photo above, you can think of the window object as a representation of the Browser. More specifically, it represents a single tab within your browser.
Some common Window methods
To get you started, go ahead and open up your browser dev tools and execute the following code.
// Opens an alert box
window.alert("I love programming");
// Opens a new browser tab
window.open("https://www.google.com");
// Scrolls (smoothly) down by exactly 1 page
// (make sure you are on a webpage that has enough content to scroll)
window.scrollBy({
top: window.innerHeight,
left: 0,
behavior: "smooth",
});
// Reloads the browser tab
window.location.reload();
Since window is a globally available object in the browser, you don't need to preface all of your commands with it. The following code will work the same as the code above.
// Opens an alert box
alert("I love programming");
// Opens a new browser tab
open("https://www.google.com");
// Scrolls (smoothly) down by exactly 1 page
// (make sure you are on a webpage that has enough content to scroll)
scrollBy({
top: innerHeight,
left: 0,
behavior: "smooth",
});
location.reload();
Some Common Window Properties
While these are some of the common "methods" that you might be using, here are some of the common "properties" that belong to the global window object. Feel free to type these into your dev tools Console.
// Width and height in pixels of the space that displays the HTML
window.innerHeight;
window.innerWidth;
// Width and height in pixels of the entire browser window
window.outerHeight;
window.outerWidth;
window.localStorage; // You'll use this later in the series for storing temporary information in the browser
window.location.href; // The URL you are currently at
// How many pixels you have scrolled vertically and horizontally within your browser tab
window.scrollX;
window.scrollY;
Some Common Window Events
This one might be a bit confusing at first, but with the DOM, you can trigger code based on certain events. Here's a simple example of how that works:
window.onscroll = function () {
console.log("stop scrolling me!!");
};
Above, we are creating a function and assigning it to the onscroll event, which is one of many events you can "plug in to" on this object. Every time you scroll on the page, you will see "stop scrolling me!!" printed to your dev tools Console.
We will come back to "events", but there are a few more things we need to learn first.
The "Document" Object
No, not the "Document Object Model". There is a literal object called document. Let's look at that picture again.
We just talked about the Browser, represented by the window object, but now, we need to talk about that HTML Document that is being displayed within the window. Every browser tab that you have open right now is a representation of a single HTML document. We can refer to this in JavaScript code via the DOM as document.
Since the HTML document is within the browser window, it makes sense that this object is a property of the window object. Even so, it is globally available, which means you don't have to precede it by window. Type any of the following code into your dev tools console and it should work just fine.
// These are both valid. `document` is a property of `window` AND it is globally accessible
window.document.baseURI;
document.baseURI;
While you can scroll, refresh, and manage tabs in your browser via window, the document object allows you to manipulate the actual contents of the webpage. Here are a few things you can do:
- Add/Remove HTML elements to the page
- Modify existing HTML elements
- Add "event listeners" to HTML elements
You can think of document as a representation of the HTML Document. This HTML Document is structured like a tree and believe it or not, you already have a basic understanding of this! Let's look at a very simple HTML document.
<html>
<head>
<title>Site Title</title>
</head>
<body>
<div class="main-body">
<h1>Article Heading</h1>
<p>Some text in the article</p>
</div>
<div class="footer">
<p>Site created by Zach</p>
</div>
</body>
</html>
See what this HTML looks like here
When we type document into our console, we will get an "object representation" of the HTML code we see above (please note that if you are typing this into your Codepen console, you might see something slightly different, which is because Codepen inserts additional HTML and CSS for certain functionality of their service).
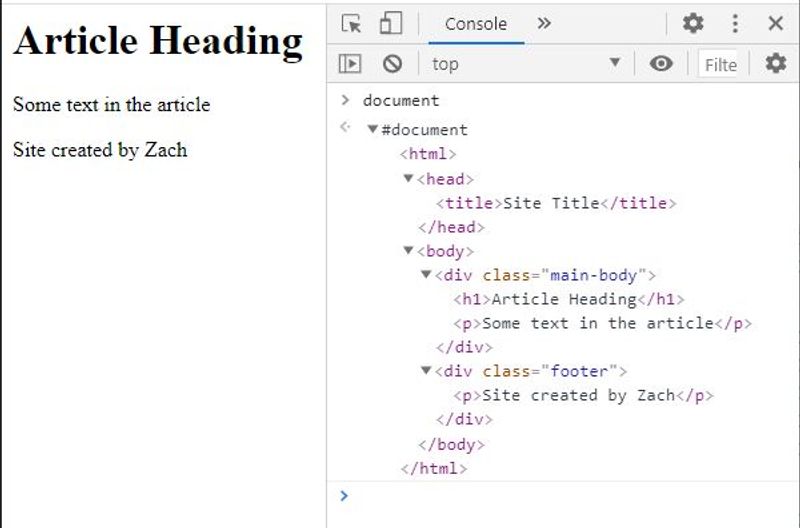
Now compare the object in the photo above to something like this:
const obj = {
prop1: {
nestedProp: "some value",
},
prop2: ["i", "am", "an", "array"],
};
If these two "objects" look different to you, that is good, because they are different. While the HTML document object appears to have properties similar to our good 'ole JavaScript object above, they work a bit differently.
This is valid:
const obj = {
prop1: {
nestedProp: "some value",
},
prop2: ["i", "am", "an", "array"],
};
console.log(obj.prop1.nestedProp);
This is NOT valid:
console.log(document.body.div.h1); // TypeError: Cannot read property 'h1' of undefined
So... How do we access the various HTML elements that are clearly stored in the document object??
The "DOM Tree"
Like we learned about before, the DOM is not a programming language, and it's not actually part of native JavaScript. It is a "model" for an HTML Document. Within that "model", we have "branches" and "leaves" just like a tree. Translated into programming-speak, we call each of these branches and leaves "Nodes". And no, this has nothing to do with NodeJS (a server-side JavaScript runtime we will be working with soon).
Here is our HTML document from earlier with a few additions:
<html>
<head>
<title>Site Title</title>
</head>
<body>
<div class="main-body">
<h1>Article Heading</h1>
<p>Some text in the article</p>
<p>Some more text</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
<div class="footer">
<p>Site created by Zach</p>
</div>
</body>
</html>
Here's how we draw this in "DOM Tree" format:

To effectively use the DOM via JavaScript, you should think of these "Nodes" like you would an ancestral hierarchy. You've got children, siblings, parents, grandparents, and great-grandparents. For example, all the li tags within the ul tag are siblings because they are at the same level in the hierarchy. Likewise, the p tags in the div with the main-body class are siblings. Body is the child of HTML while both of the div nodes are children of the Body node.
The above picture is a simplified view. Each "Node" has unique characteristics, and there are a couple common node types (here's a comprehensive list):
- Element Nodes
- Text Nodes
- Attribute Nodes
I'm going to bring back a diagram that you've probably seen before:

Now let's relate this to these "Nodes".
The <p></p> tag is an "Element Node". The class="some-class" is an "Attribute Node". The Content value is a "Text Node". Here, I'll prove it to you by creating this exact element in JavaScript:
// Create empty containers for each node type
const elementNode = document.createElement("p");
const textNode = document.createTextNode("Content");
const attributeNode = document.createAttribute("class");
console.log(elementNode); // <p></p>
console.log(textNode); // "Content"
console.log(attributeNode); // class=""
// Start constructing the HTML element
// Currently, our element is: <p></p>
elementNode.appendChild(textNode);
// Currently, our element is: <p>Content</p>
attributeNode.value = "some-class";
elementNode.setAttributeNode(attributeNode);
// Currently, our element is: <p class="some-class">Content</p>
console.log(elementNode);
// This inserts our new HTML element at the bottom of whatever webpage you are currently on (try it out!)
document.body.appendChild(elementNode);
Congrats! We just recreated an HTML element with JavaScript! I used some API methods that we haven't talked about, but hopefully you can see what is happening here in a general sense. For example, appendChild() will take an existing node and insert it between another node.
What is the point of doing this though? I can think of a few examples:
- A user creates a calendar event and you need to display it in an existing webpage
- A user adds an item to their todo app
- A user creates a post on facebook
All of these actions require HTML to be created on the fly (via JavaScript).
Now that we have covered some basics of the DOM, let's see how we can use it. Please know that in the following example, we will not be covering everything there is to know about the DOM API. As I mentioned earlier, the goal is to get acquainted with the DOM and understand how and why it is used; not master it.
A DOM Example
Now that you have a baseline understanding of how the DOM works, let's put it in action! Let's take a look at that HTML document from earlier:
Let's say our objective is to add a line of text (i.e. a p element with some text in it) every time we click the button. Here are the steps we must take:
- Find a way to identify the
buttonHTML element using the DOM API - Register a "click event" on this HTML element (i.e. tell it what to do when it is clicked)
- Write a function that will add a
pelement to the HTML Document (DOM) every time the button is clicked
Step 1: Identify the button
To identify an Element type using the DOM, we have several ways of doing this. First, let me show you what the HTML looks like for the button above, because without seeing it, you cannot effectively identify it.
<button id="btn-1" class="my-btn">CLICK ME</button>
Let's walk through this. The id attribute is a global HTML attribute that can be used on ANY type of HTML element. I have assigned btn-1 as the ID for this element, but you could have named it anything you want. You could even name it my-btn; the same exact name given to the class attribute, which is also a global attribute available to all HTML elements.
We as the developer have assigned this button HTML element an ID and a class, which means we have many ways to identify it. The first way we can identify this is the most generic:
document.querySelector("button"); // "<button id='btn-1' class='my-btn'>CLICK ME</button>"
In this case, we are using the querySelector() built-in method and selecting based on the tag name (button) of the element, which will return the first occurrence of an HTML tag in the HTML document. Here, you can learn more about this method.
There is no problem with this method in our HTML example because we only have 1 button in the entire HTML document! But if later, we added another button, this method of selection will cause us problems because we are not being specific enough. Here's a better way to identify it.
document.getElementsByClassName("my-btn"); // HTMLCollection [button#btn-1.my-btn, btn-1: button#btn-1.my-btn]
But wait a second... When using this method, we are not returned a single element! That is because in HTML, you can assign a single class name to multiple HTML elements. Therefore, the getElementsByClassName() will return an HTMLCollection type, which is basically a fancy Array of HTMLElement types. That's probably not what we're looking for here since we only want to identify a single button.
Read more about getElementsByClassName() here.
Let's try another way.
document.getElementById("btn-1"); // "<button id='btn-1' class='my-btn'>CLICK ME</button>"
Ahhhh, that's better! Unlike the class attribute, you can only assign an ID to one element within the document. This would be INVALID:
<button id="btn">Button 1</button> <button id="btn">Button 2</button>
We CANNOT have two button elements that both have an ID of btn! So going back to our getElementById() method, we know that we are being specific AND we will only be searching for a single HTML element within the document.
But to this point, I've been leading you in unnecessary directions. We could have modified our first method, querySelector() to identify this button by its tag, class, or ID!
// Get the first occurrence of <button></button> within the HTML document
document.querySelector("button");
// Get the first occurrence of an HTML element that has a class of "my-btn" in the HTML document
document.querySelector(".my-btn");
// Get the HTML element that has an ID of "btn-1"
document.querySelector("#btn-1");
Notice anything in this code above? I do. It looks like we are adding in . and # before the identifier to look for a class and ID respectively. Keep this in mind, you'll see it again when we start talking about CSS in the next lesson.
While all three of these methods will return us the same result for this specific HTML document, that will not always be the case. Remember, be as specific as possible when identifying HTML elements.
Below, I have written all the ways we could identify that button in our HTML. The first couple methods will return you an individual HTMLElement while the second section will return an HTMLCollection (again, just a fancy Array of HTMLElement types).
// Will return a single HTML Element
document.querySelector("button");
document.querySelector(".my-btn");
document.querySelector("#btn-1");
document.getElementById("btn-1");
// Will return an HTMLCollection (multiple HTML elements stored in an Array)
document.getElementsByClassName("my-btn");
// Will return a NodeList (very similar to HTMLCollection)
document.querySelectorAll("button");
document.querySelectorAll(".my-btn");
document.querySelectorAll("#btn-1");
I know we haven't discussed HTMLCollection, NodeList, etc. yet, but stick with me. Now that we have our button identified, let's do something cool with it.
Step 2: Register a "click" event on the button
C'mon Zach, you're teaching me ANOTHER new concept??
I know, this is a lot. But we are about to talk about something called "event handling", which is a big part of programming front-end applications. "Events" are not specific to front-end programming though; you will soon learn that events are a huge part of programming in general.
In front-end programming, an "event" is something that occurs as a RESULT of a user action. Here are some examples:
- A user hovers their mouse over an HTML element (like a button)
- A user scrolls down to read the rest of an article
- A user clicks a button
- A user starts typing into an
<input>field
There are many more events that can occur, but if I had to pick the most common one based on my experience, it would be a "click" event.
But how do we work with these "events"?
So far, you know how we can identify a single HTML element within the HTML document by using the DOM. Once you have identified that element, you can assign it to a variable.
const myButton = document.querySelector("#btn-1");
Hint: within the Codepen editor for this HTML example, you can right-click and "Inspect Element" to get to the console still. I suggest doing so and following along here!
The variable myButton now represents an Element, which has properties, methods, and events attached to it. I suggest you take a look at each for a minute or two:
In other words, we have a really powerful JavaScript object that we can use to make our HTML document come to life!
There are two ways that we can register an "event listener" on this specific HTML element.
Here's the first:
const myButton = document.querySelector("#btn-1");
// eventObj is automatically passed as an argument to this callback function
function respondToClick(eventObj) {
const randomNum = Math.floor(Math.random() * 100);
console.log("The random number is: " + randomNum);
}
// Pass in a callback function for this click event
myButton.addEventListener("click", respondToClick);
And here's the second:
const myButton = document.querySelector("#btn-1");
// eventObj is automatically passed as an argument to this callback function
function respondToClick(eventObj) {
const randomNum = Math.floor(Math.random() * 100);
console.log("The random number is: " + randomNum);
}
// Pass in a callback function for this click event
myButton.onclick = respondToClick;
Go ahead, paste these code snippets (one at a time of course) in the JavaScript section of this Codepen.
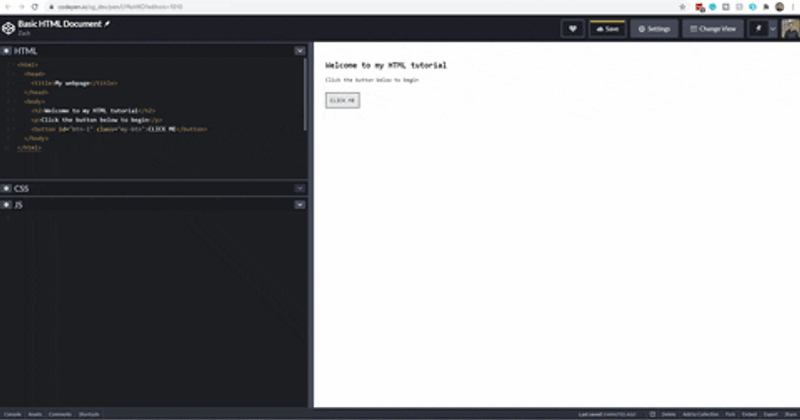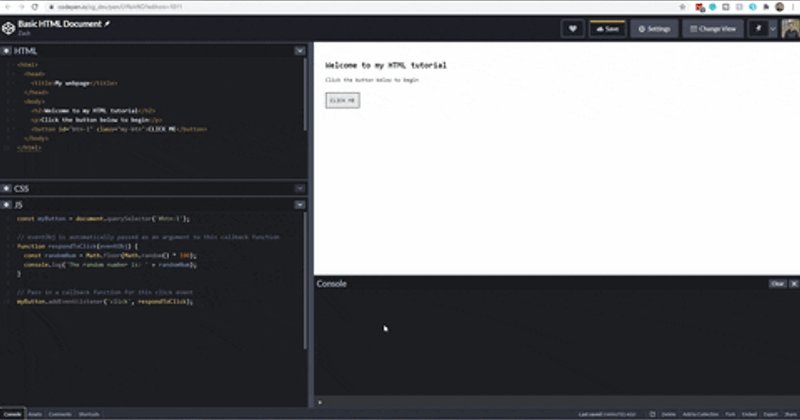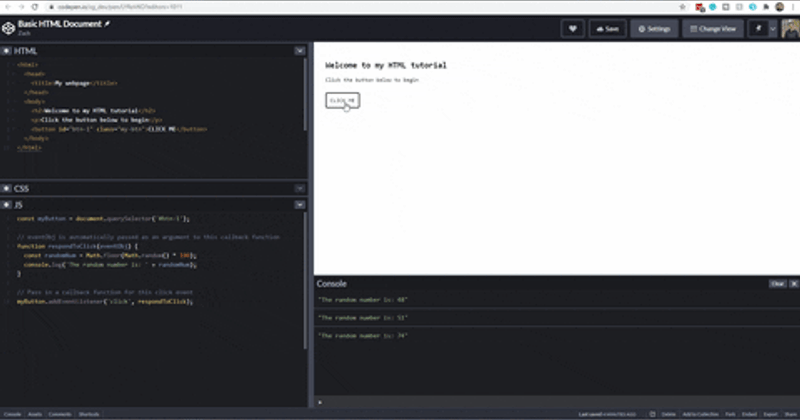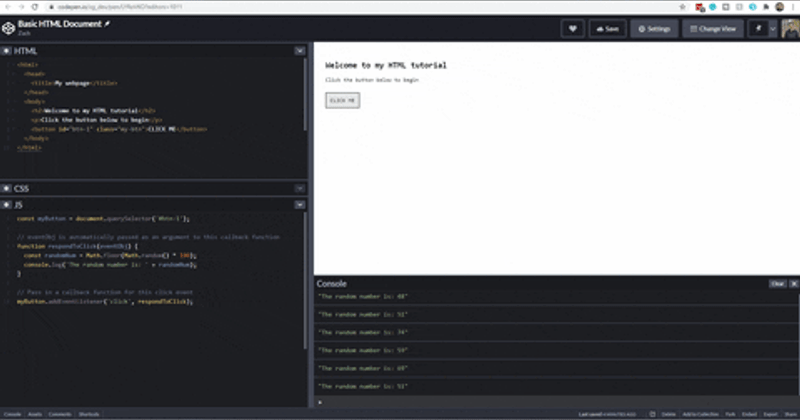
There is nothing remarkable about what we are doing here. We select an element from our HTML document using the DOM (document.querySelector()), write a function that prints a random number to the console, and then instruct our HTML element, myButton to respond to click events by running that function, respondToClick().
You might ask, how did I know to pass in click to the addEventListener() method, or how did I know to use onclick in the second version?
The easiest way to learn about events is by reading through the Events Reference page on MDN. I suggest clicking around (no pun intended) in that documentation for a few minutes to get a sense of what events are available to you in the browser as a developer.
Step 3: Add an element to the HTML Document Programmatically
We're almost there! We now just have to adapt our respondToClick function so that it will add a new p element to the DOM every time the button is clicked. We don't need to get fancy; let's just add a p tag with the same text that we are currently printing to the Console.
In order to do this, we'll need to use some DOM methods that help us modify the existing HTML document and its elements. Let's take a look at the reference for the document object. You can find it here.
Remember, document is the "global" object and represents the "entry point into the web page's content". Since our HTML document is rather small in this case, we can use this global object to insert p tags at the end of the content. Here are the methods we'll need to make this happen:
Document.createElement()- Allows us to create a newpHTML element (i.e. it will initialize something like<p></p>)Document.createTextNode()- Allows us to create the text which we will insert into our new elementNode.appendChild()- Allows us to add our new "text node" to our new paragraph element (<p></p>)
Let's see how it works:
const myButton = document.querySelector("#btn-1");
// eventObj is automatically passed as an argument to this callback function
function respondToClick(eventObj) {
// Generate some random text
const randomNum = Math.floor(Math.random() * 100);
const pContent = "The random number is: " + randomNum;
// Initialize a `p` tag - <p></p>
const newElement = document.createElement("p");
// Initialize some text content
const newTextNode = document.createTextNode(pContent);
// Insert the text content between <p> and </p> from the element we initialized earlier
newElement.appendChild(newTextNode);
// Insert the new `p` element at the end of the HTML <body></body> tag
document.body.appendChild(newElement);
}
// Pass in a callback function for this click event
myButton.addEventListener("click", respondToClick);
And now, when we click the button, it inserts a new element to the HTML document!
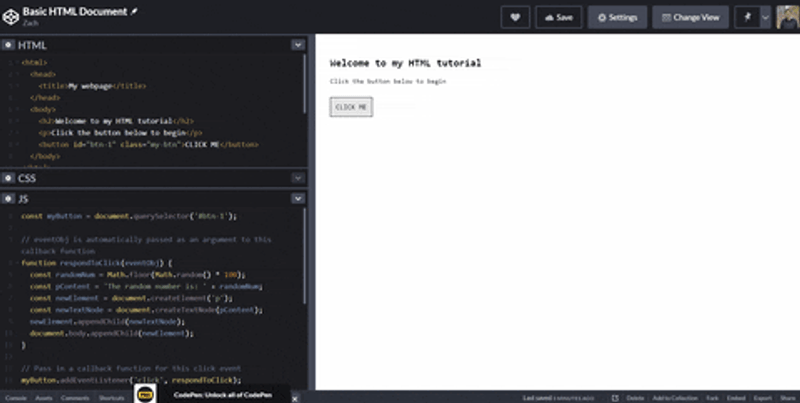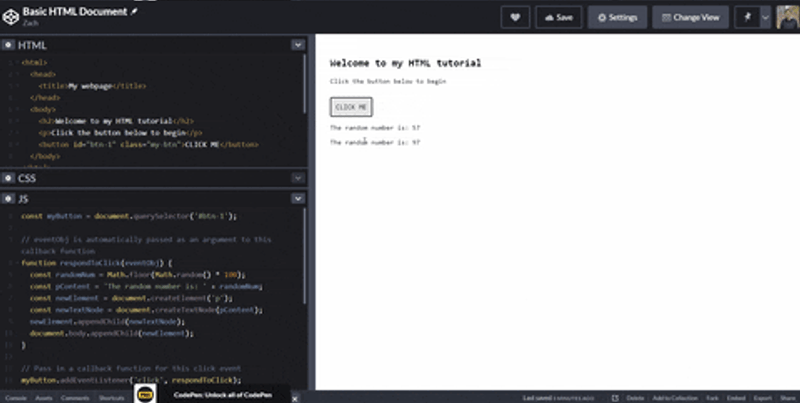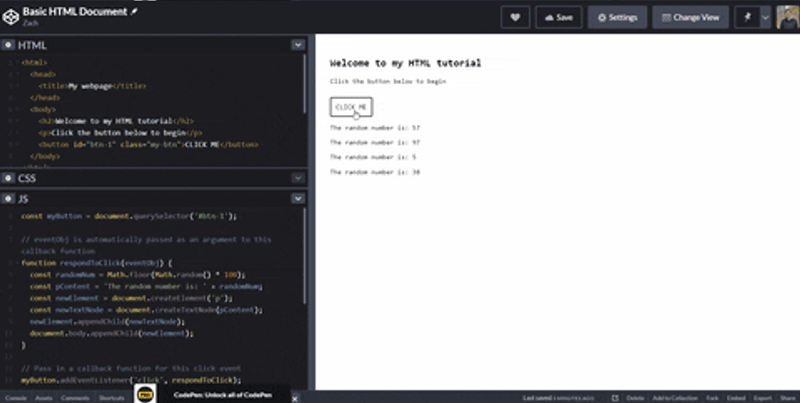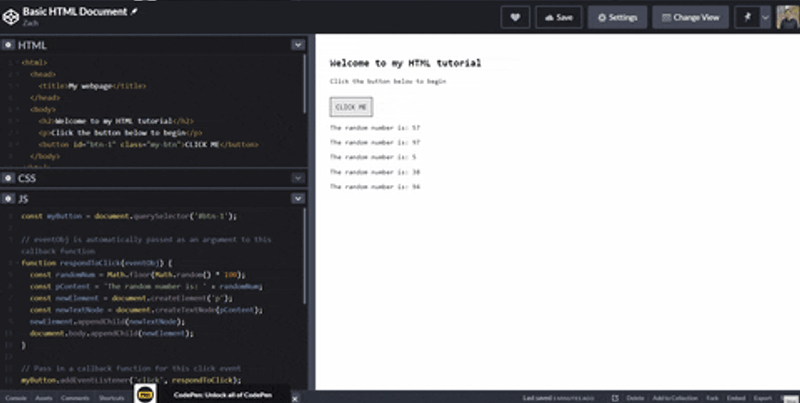
You can see the working Pen here.
Navigating an HTML Document
Let's return to the HTML document we looked at previously.
<html>
<head>
<title>Site Title</title>
</head>
<body>
<div class="main-body">
<h1>Article Heading</h1>
<p>Some text in the article</p>
<p>Some more text</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
<div class="footer">
<p>Site created by Zach</p>
</div>
</body>
</html>
The example we just walked through was wide, but not deep. While we covered how to select, insert, and respond to events, we did not talk about techniques for parsing through an HTML document. For example, how would we...
- Select and modify the second item of the list?
- Add a fourth element to the list?
- Add another
pelement after the secondpelement?
To accomplish this, we need to remember that every HTML document is just a "tree".
Furthermore, if we connect the dots a little bit, we can recognize that "sibling" nodes in an HTML document might make sense to store in an Array. Let's see that in action.
Selecting "children" elements
Our first task is to modify the second element of our list. To do this, I'm thinking we do the following:
- Find a way to identify the list within the HTML document
- Find a way to select an individual element from the list
Based on what we have talked about, I would not expect you to know how to do this yet. The purpose here is to get you into the "DOM mindset" and expose you to some common ways that you might use the DOM API in your projects.
So let's start by identifying that list within our HTML document. There are MANY ways that we can do so, but I'll start with the most logical one.
Since we only have one ul tag in the entire document, we can use a basic query selector.
const list = document.querySelector("ul");
As with any tutorial, my goal is to make you self sufficient, so the first question we should be asking here is, "what type of node is this?". With the DOM, it is often tough to know what type of node you are dealing with whether that be a text node, attribute node, or element node. If at any point you don't know what you're working with, here's how you figure it out.
const list = document.querySelector("ul");
console.log(list.nodeType); // 1
You can use the nodeType property that exists on ALL nodes. But what does 1 represent? Here's a table that tells you. In this case, we are working with an Element. From this information, we can visit the Element documentation and take a look at some of the properties and methods available to us.
If you visit the Element docs, you'll see that one of the available properties on an Element node is children. Since the li tags are "children" to the ul "container" tag, this seems like a property that might help us.
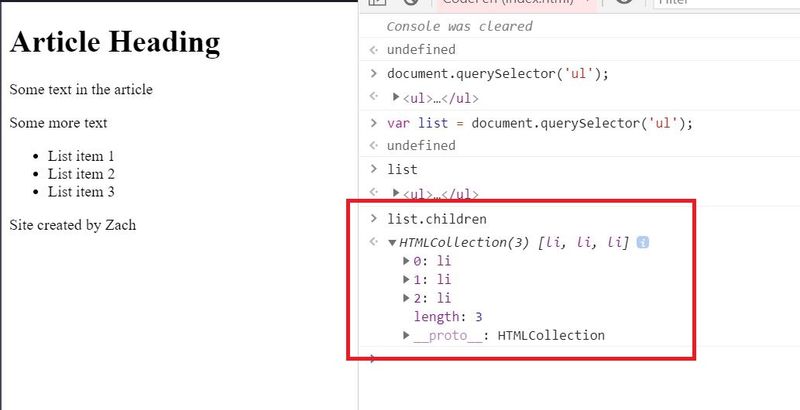
As you can see, it's kind of like an Array, but not quite. Go ahead and take a look at the HTMLCollection documentation. While here, you'll notice that there is a method called item(), which we can pass an "array index" to get a certain element from the HTMLCollection "Array".
const list = document.querySelector("ul");
// Remember, arrays are "zero-indexed"
const secondListItem = list.children.item(1);
Now that we have identified our element, all we have to do is modify it. In this case, secondListItem is an Element type, which has an editable property called textContent. Let's use this to change the value of the second element in our list.
const list = document.querySelector("ul");
// Remember, arrays are "zero-indexed"
const secondListItem = list.children.item(1);
secondListItem.textContent = "a new value";
Awesome! We have modified the second element of HTML list.
Now here's something important to remember–the change you just made is temporary. If you are rendering static HTML code in the browser, JavaScript cannot directly edit it. Once you refresh the page, your second list item will return to the original value. Knowing this, you might ask, "if the changes are temporary, what's the point?". This is a tough question to answer at our current level of understanding, but a very good question. The answer will reveal itself to you as we get deeper into this series, but here's my short answer–the user needs to see changes in real time. If your user has to wait 2 seconds or even refresh the page every time he/she takes an action, the user experience will be poor.
Creating elements
Our next goal is to add a fourth element to our list. Remember, our ul list is an Element, which has properties and methods that we can use. But if you read through its documentation, you probably won't find anything that helps us here...
And this brings up a very important (but kind of confusing) concept–inheritance. Remember how I talked about how everything in the "DOM Tree" is a "node"? Well, I meant it. It doesn't matter whether we are working with an Element, Attribute, or Text. They all "inherit" from the Node type, which means they all can use the properties and methods on the Node type along with their own properties and methods. This is an OOP (object oriented programming) concept and can be quite confusing. We will learn more about this later in the series.
Anyways, since there is nothing useful to us on the Element type, let's take at the documentation for the Node type.
It has a method called appendChild() that will help us add that fourth list item!
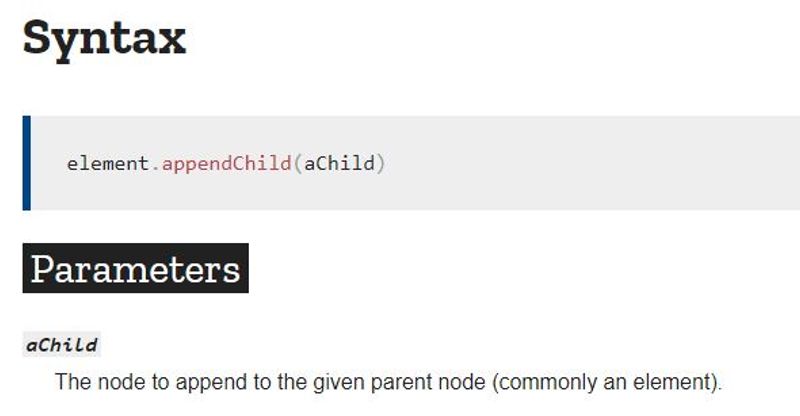
Notice that the parameter it specifies, aChild, is a node. In our case, we probably want to create another li element, which we can do with the document.createElement() method.
const list = document.querySelector("ul");
// Creates <li></li>
const newListItem = document.createElement("li");
// Creates <li>Fourth list item</li>
newListItem.textContent = "Fourth list item";
// Adds the new element to the existing list
list.appendChild(newListItem);
If you're really paying attention to this article closely, you might remember that when we created a new element earlier, we did something like this to add the text to the element.
const newListItem = document.createElement("li");
const textNode = document.createTextNode("Fourth list item");
newListItem.appendChild(textNode);
This is just another way to solve the problem. You'll learn that with the DOM and programming in general, there are ALWAYS several ways to achieve the same thing.
Adding elements between other elements
Our final objective is to add the following p element after the first p element.
<p>Some inserted text</p>
So... What element do we need to select? The Node type has a method called insertBefore() which we can use to insert our p element before the second p element (hence, after the first p element).
Here's a problematic way to identify that second p item.
const pItem = document.querySelector("p");
Why is this problematic? If you try it out, you'll realize that this selects the first p element and ONLY the first p element. Let's try this:
const pItems = document.querySelectorAll("p");
Better, but not great. This will give us all the p elements in the entire document, including the one in the <div class="footer"></div> element. Let's get a little bit more specific with our query.
// First, select the div with a class of "main-body"
const mainBody = document.querySelector(".main-body");
const pItems = mainBody.querySelectorAll("p");
This is much better. The pItems variable will be a NodeList, which is similar to HTMLCollection which we looked at earlier. We can use the item() method on it to select the second p element.
// First, select the div with a class of "main-body"
const mainBody = document.querySelector(".main-body");
const pItems = mainBody.querySelectorAll("p");
const secondParagraphElem = pItems.item(1);
Now, we just need to insert a new p element after this selected element.
// Step 1: Find the element we want to insert something after
const mainBody = document.querySelector(".main-body");
const pItems = mainBody.querySelectorAll("p");
const secondParagraphElem = pItems.item(1);
// Step 2: Create the element we want to insert
const newElem = document.createElement("p");
newElem.textContent = "some inserted text";
// Step 3: Insert the element
mainBody.insertBefore(newElem, secondParagraphElem);
You'll notice that the insertBefore() method has two parameters. If you read the documentation, you'll learn that we need to call this method on the "parent element" that we want to insert the new element in. In this case, the "parent element" is mainBody (look at the DOM Tree diagram earlier in this post). The first parameter is the element you want to insert, which is newElem. And the second parameter is the "reference element", which represents the element you want to insert your new element before. In this case, that is secondParagraphElem.
If you want to see all of this code in action, check out this Pen I made!
The DOM is Confusing
If you're still reading, good. You've got the type of mind for this challenging skill we call programming. That said, you're probably still confused with this "DOM" concept, and I don't blame you. There is a LOT going on with the DOM and I could easily create an entire programming course on it alone. It would take weeks to cover all of the DOM interfaces, methods, properties, and events.
For that reason, we're stopping here. My goal here was to introduce you to the DOM, so I hope I did that effectively.
As we move forward through this full-stack series, you probably won't be working with the DOM a ton. The reason? Because front-end frameworks like Angular, React, and Vue abstract the DOM away and provide you with easier ways to manipulate it.
That does NOT mean learning the DOM is unimportant. Quite the contrary! Knowing how the DOM works and being able to use it will give you an edge on other web developers who never spent the time to learn it.
So if you don't feel confident with the DOM, that's okay. Keep moving forward. If you can explain the basic concept of the DOM and do super basic things with it, you are in a great spot!
A Recap of HTML
Remember, if we are building a house, HTML is the structure, CSS is the styling, and JavaScript is the functionality. To me, HTML can be expressed in two ways:
- Static HTML
- Dynamic HTML
Static HTML is what we learned in the first part of the lesson. When you write static HTML, you are basically telling your browser, "Here's the document I want you to display, and it's never going to change". Static HTML is all over the web. Most blogs and writing on the web are just static HTML documents.
Dynamic HTML is the second part of this lesson. By "modeling" an HTML document, we can plug into it with JavaScript (via the DOM) and make some crazy things happen! This is required for web apps like YouTube, Facebook, and others. While we could use the DOM alone to bring this functionality to our apps, there are easier ways to do this (i.e. front-end frameworks like Angular, React, Vue, etc.).
Writing "Semantic" HTML (the new parts)
The last thing I want to cover in this crash course on HTML is something that is not required for you at this stage in your journey, but helpful to know about.
Let's go back to that house analogy. If HTML is the "structure" of the house, what does that include? I'm no home-builder, but to build a house, you need more than just 2x4s. You need multiple types of wood, and additionally, other materials for certain sections of the house you are building.
HTML is no different. While we could build our HTML documents with a bunch of div elements, that is not "semantic". In other words, we are not conveying what the elements are meant to contain effectively.
There are many HTML tags that I did not show you during the first part of this post to avoid over-complicating the discussion. But from a semantic standpoint, it is "best practice" to use HTML elements that convey what the elements represent in your document.
Most of the elements I am about to show you were introduced in the HTML5 standard, which is the newest standard of HTML. Consider the following HTML document:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>My Blog</title>
<meta name="description" content="An example blog site" />
<meta name="author" content="Zach Gollwitzer" />
<link rel="stylesheet" href="css/styles.css" />
</head>
<body>
<div class="navbar">
<ul>
<li>Home</li>
<li>About</li>
<li>Blog</li>
</ul>
</div>
<div class="sidebar">
<div>Some sidebar offering here</div>
</div>
<div class="main-content">
<div class="article-1">
<p>Some text for the blog post</p>
</div>
<div class="article-2">
<p>Some text for the blog post</p>
</div>
<div class="article-3">
<p>Some text for the blog post</p>
</div>
</div>
<div class="footer">
<p>Some footer text</p>
<p>Copyright, 2021</p>
</div>
<script src="js/scripts.js"></script>
</body>
</html>
If we added some CSS (styling) to this HTML document, we'd have a blog page with a navigation bar at the top, a sidebar on the right, a list of blog posts in the main area, and a footer at the bottom. Here's my golf blog as an example of the layout I'm describing.
The HTML document above is fine. It works perfectly. But as you can see, we're using a lot of div elements despite the fact that each section of this document has a different purpose. When I say "semantic HTML", I'm referring to this:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>My Blog</title>
<meta name="description" content="An example blog site" />
<meta name="author" content="Zach Gollwitzer" />
<link rel="stylesheet" href="css/styles.css" />
</head>
<body>
<nav class="navbar">
<ul>
<li>Home</li>
<li>About</li>
<li>Blog</li>
</ul>
</nav>
<section class="sidebar">
<div>Some sidebar offering here</div>
</section>
<main class="main-content">
<article class="article-1">
<p>Some text for the blog post</p>
</article>
<article class="article-2">
<p>Some text for the blog post</p>
</article>
<article class="article-3">
<p>Some text for the blog post</p>
</article>
</main>
<footer class="footer">
<p>Some footer text</p>
<p>Copyright, 2021</p>
</footer>
<script src="js/scripts.js"></script>
</body>
</html>
Can you see the difference? In the second version, I'm using the following HTML tags that we haven't covered before:
<nav></nav>- here is the documentation<section></section>- here is the documentation<main></main>- here is the documentation<article></article>- here is the documentation<footer></footer>- here is the documentation
Furthermore, tags like strong and em that I introduced to you at the beginning of the post work fine, but in the new HTML5 standard, are not technically "recommended". The idea with the newest HTML standard is that each HTML tag should represent intent, not style. For example, the section tag indicates that everything within it is part of an independent section of the webpage. You shouldn't use this tag for any other purpose.
Now if we zoom out a bit, these details that I'm introducing should not be at the top of your priority list. These are details that you'll focus on down the road when you are trying to master your craft.
I bring them up here so that you are not surprised when you see them in another developer's code.
Remember, the documentation is your friend! If you stumble upon something you haven't seen before, just look it up! If you don't know what a certain tag should be used for, read the documentation page for it!
Finally, your HTML Challenge
From this point forward, our lesson challenges are going to be a lot more fun than the previous lessons. Rather than writing plain JavaScript code, all challenges from here forward will combine HTML, CSS, and JavaScript. Not only that, but you'll now have something to share with the world!
When you complete these challenges, be sure to share them on Twitter with the hashtag, #100DaysOfCode.
And don't forget, we call this a "challenge" because it is very challenging. You should not be able to complete this without some additional research!
Challenge Instructions
- Fork this Codepen to your account (click the "Fork" button in the bottom right corner of the browser window)
- Create this:
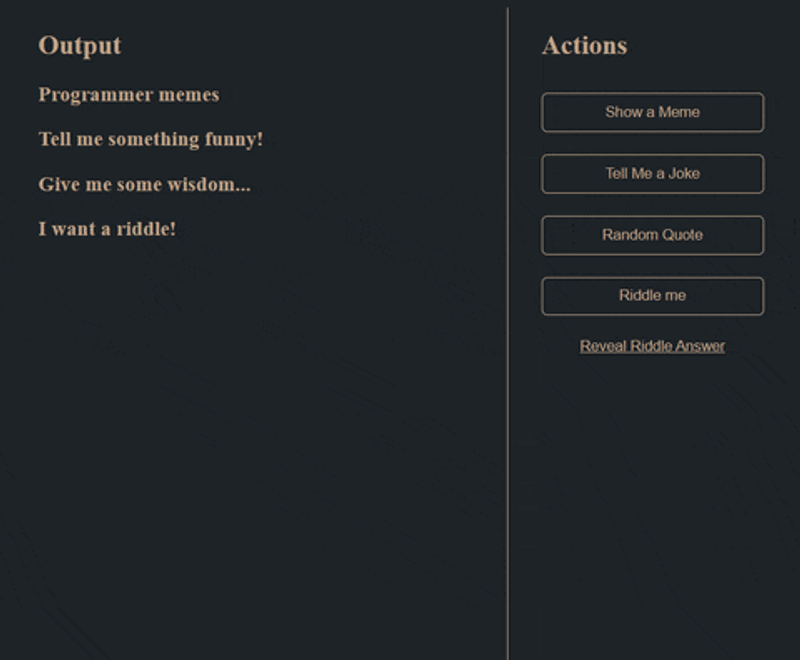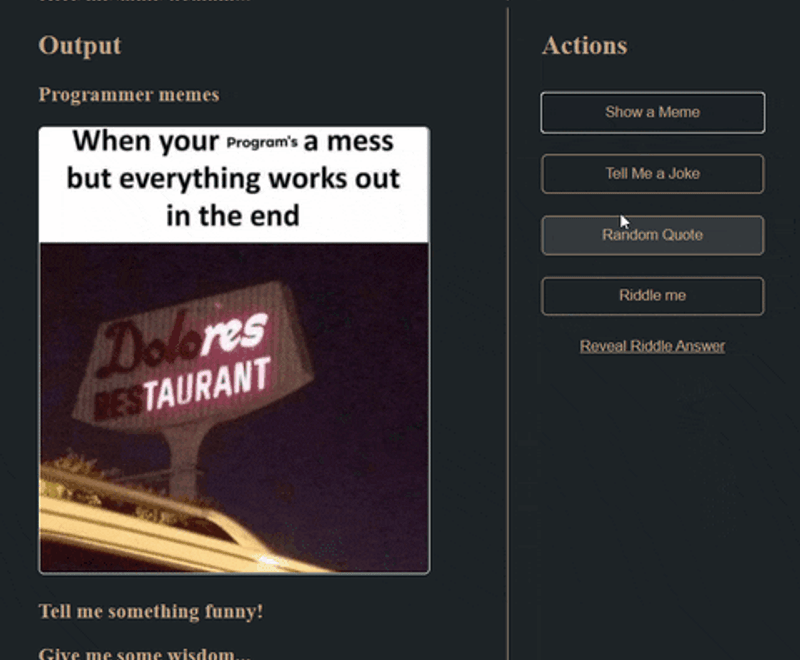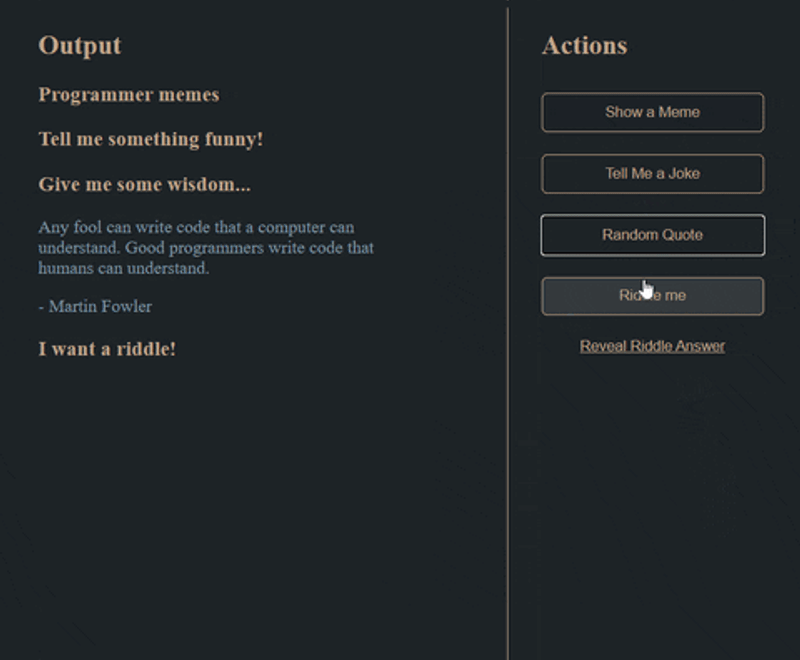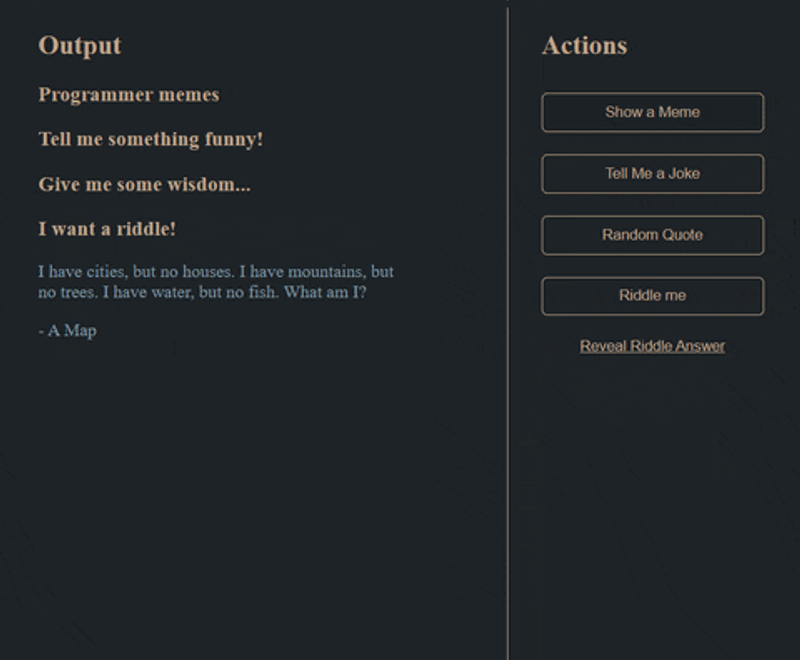
User Stories
A "user story" is something you'll use often in programming. It defines how a user should interact with your application and is commonly used during the requirements gathering phase of application development. Below are the user stories for this challenge.
- A user should be able to click buttons on the right side of the screen to generate a random meme, joke, quote, or riddle
- Only one piece of content should show at a time. For example, if the user clicks "Show a meme" and there is a quote showing already, the application should remove the quote and show a random meme.
- Content should be displayed under the appropriate heading (i.e. a joke should not show up under the memes heading)
- When showing a random riddle, the answer should never be revealed without the user explicitly clicking the "Reveal Riddle Answer" button on the right.
- If a user clicks "Reveal Riddle Answer" and there is no riddle, an alert should let them know they need to generate a riddle first
- If a user clicks "Reveal Riddle Answer" and the answer is already revealed, an alert should let them know that the answer is already revealed
Some Hints
Like I said, this programming challenge is tough. You'll need to look things up on Google. Here are some hints to help:
- The
divelement with a unique id or class name can be a great way to establish a "container" for future content (even before that content exists) - You might need to use the HTMLElement.hidden property for the riddles
- There is no "perfect" solution. Solve it how you think makes sense
- The starter has some code already written for you. Read it and see what it is doing! You should be able to solve this without adding any additional functions.
The Solution
If you want to see how I implemented it, you can either...